테이블 세그먼트와 레플리카
이 주제는 ClickHouse Cloud에는 적용되지 않습니다. ClickHouse Cloud에서는 Parallel Replicas가 전통적인 shared-nothing ClickHouse 클러스터에서의 여러 세그먼트처럼 동작하며, 객체 스토리지는 레플리카를 대체하여 고가용성과 장애 허용을 보장합니다.
ClickHouse에서 테이블 세그먼트(table shard)란 무엇입니까?
기존 shared-nothing ClickHouse 클러스터에서는 ① 데이터가 단일 서버에 저장하기에는 너무 크거나 ② 단일 서버가 데이터를 처리하기에 너무 느린 경우 세그먼트(샤딩, sharding)를 사용합니다. 다음 그림은 uk_price_paid_simple 테이블이 한 대의 머신 용량을 초과하는 ①의 경우를 보여 줍니다:
이러한 경우 데이터는 테이블 세그먼트 형태로 여러 ClickHouse 서버에 분산 저장할 수 있습니다:
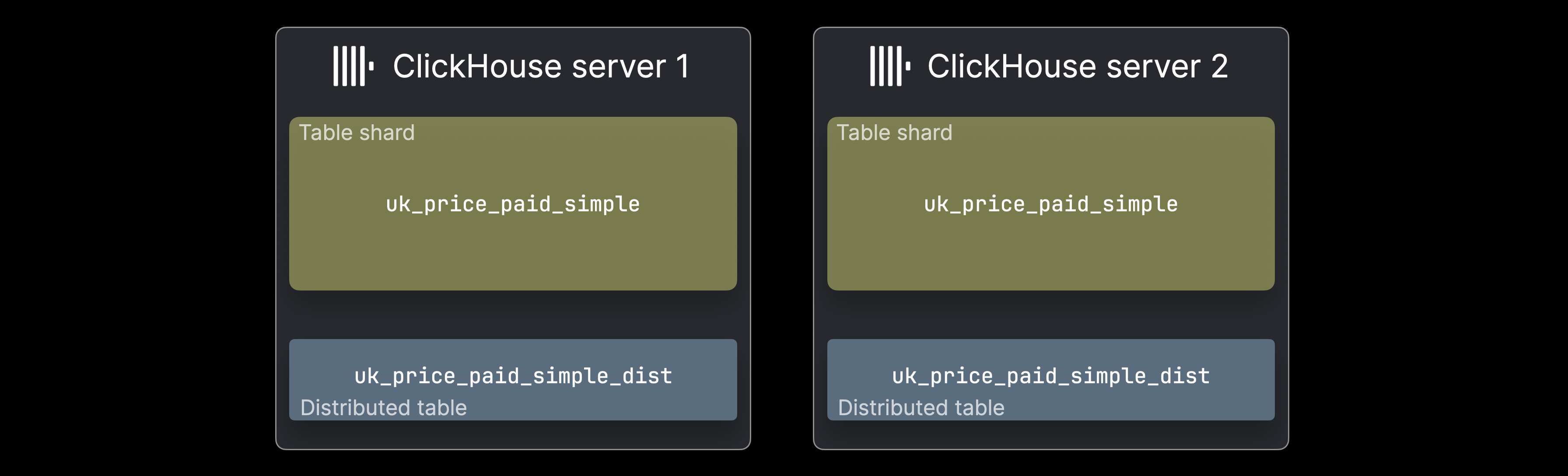
각 세그먼트는 데이터의 하위 집합을 보유하며, 독립적으로 조회할 수 있는 일반적인 ClickHouse 테이블처럼 동작합니다. 다만 쿼리는 해당 하위 집합만 처리하므로, 데이터 분포에 따라서는 이것만으로 충분한 사용 사례도 있습니다. 보통 서버당 하나씩 구성되는 분산 테이블은 전체 데이터셋에 대한 통합된 뷰를 제공합니다. 이 테이블은 자체적으로 데이터를 저장하지 않고, SELECT 쿼리를 모든 세그먼트로 전달해 결과를 조립하며, INSERTS를 라우팅하여 데이터를 고르게 분산합니다.
분산 테이블 생성
SELECT 쿼리 전달과 INSERT 라우팅을 설명하기 위해, 두 개의 ClickHouse 서버에 있는 두 개의 세그먼트로 나뉜 테이블 파트란 무엇인가 예제 테이블을 살펴봅니다. 먼저, 이 구성을 위한 해당 **분산 테이블(Distributed table)**을 생성하는 DDL 문을 보여 줍니다:
ON CLUSTER 절은 DDL 문을 분산 DDL 문으로 만들어, ClickHouse가 test_cluster 클러스터 정의에 나열된 모든 서버에 테이블을 생성하도록 합니다. 분산 DDL에는 클러스터 아키텍처에서 추가적인 Keeper 컴포넌트가 필요합니다.
Distributed 엔진 파라미터에서는 cluster 이름(test_cluster), 세그먼트 대상 테이블의 데이터베이스 이름(uk), 세그먼트 대상 테이블의 이름(uk_price_paid_simple), 그리고 INSERT 라우팅을 위한 sharding key를 지정합니다. 이 예시에서는 rand 함수를 사용하여 행을 무작위로 세그먼트에 할당합니다. 하지만 사용 사례에 따라, 복잡한 표현식을 포함해 어떤 표현식이든 샤딩 키로 사용할 수 있습니다. 다음 섹션에서는 INSERT 라우팅이 어떻게 동작하는지 보여 줍니다.
INSERT 라우팅
아래 다이어그램은 ClickHouse에서 분산 테이블로의 INSERT가 어떻게 처리되는지 보여줍니다:
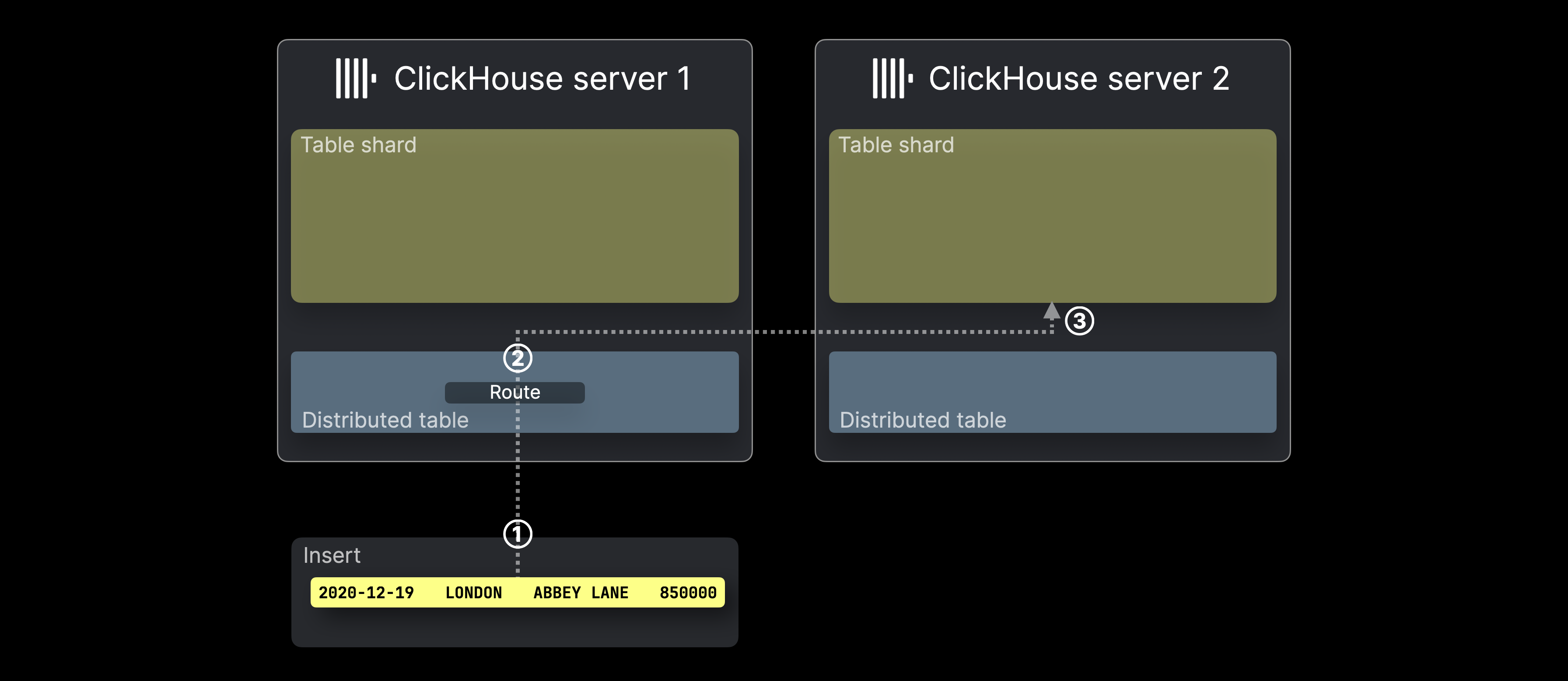
① 분산 테이블을 대상으로 하는 INSERT(단일 행)가 로드 밸런서를 거치거나 직접, 해당 테이블을 호스팅하는 ClickHouse 서버로 전송됩니다.
② INSERT에 포함된 각 행(예시에서는 한 개의 행)에 대해 ClickHouse는 샤딩 키(여기서는 rand())를 평가한 후, 그 결과를 세그먼트 서버 수로 나눈 나머지를 계산하고, 이를 대상 서버 ID로 사용합니다(ID는 0부터 시작하여 1씩 증가합니다). 그런 다음 해당 행은 전달된 뒤 ③ 대응하는 서버의 테이블 세그먼트에 INSERT됩니다.
다음 섹션에서는 SELECT 포워딩 방식에 대해 설명합니다.
SELECT 전달
이 다이어그램은 ClickHouse에서 분산 테이블을 사용해 SELECT 쿼리가 처리되는 방식을 보여줍니다:
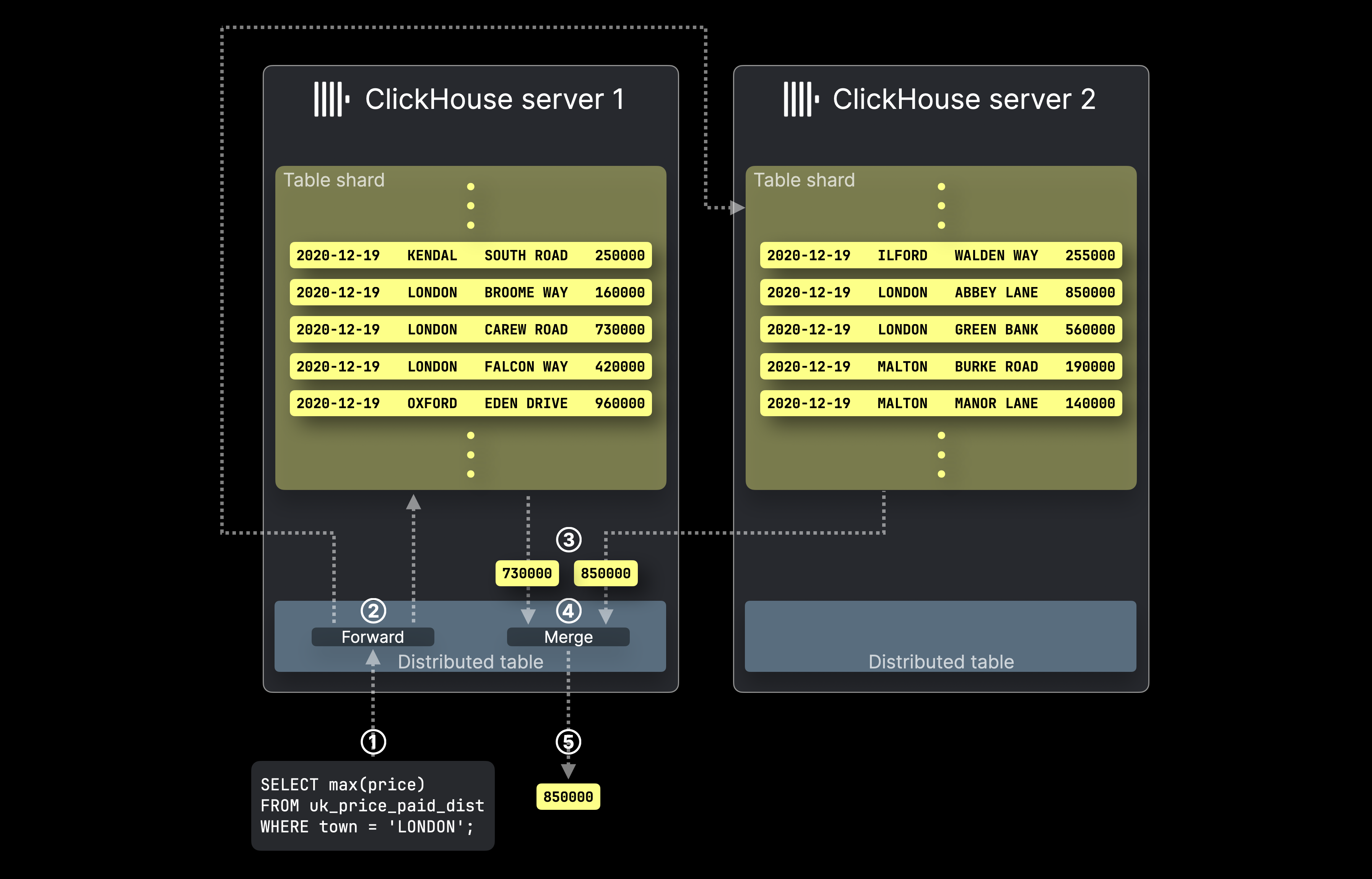
① 분산 테이블을 대상으로 하는 SELECT 집계 쿼리가 직접 또는 로드 밸런서를 통해 해당 ClickHouse 서버로 전송됩니다.
② Distributed table은 대상 테이블의 세그먼트를 호스팅하는 모든 서버로 쿼리를 전달하며, 각 ClickHouse 서버는 로컬 집계 결과를 병렬로 계산합니다.
그런 다음, 처음에 대상이 된 분산 테이블을 호스팅하는 ClickHouse 서버가 ③ 모든 로컬 결과를 수집하고, ④ 이를 최종 전역 결과로 병합한 후, ⑤ 쿼리 발신자에게 반환합니다.
ClickHouse의 테이블 레플리카란 무엇입니까?
ClickHouse의 복제는 여러 서버에 세그먼트 데이터의 복사본을 유지하여 데이터 무결성과 failover를 보장합니다. 하드웨어 장애는 불가피하므로, 복제는 각 세그먼트에 여러 레플리카를 두어 데이터 손실을 방지합니다. 쓰기는 직접 수행하거나, 작업에 사용할 레플리카를 선택하는 분산 테이블을 통해 어느 레플리카로든 보낼 수 있습니다. 변경 사항은 다른 레플리카로 자동 전파됩니다. 장애가 발생하거나 유지 관리가 수행되는 경우에도 데이터는 다른 레플리카에서 계속 사용 가능하며, 장애가 발생한 호스트가 복구되면 최신 상태를 유지하도록 자동으로 동기화됩니다.
복제에는 클러스터 아키텍처의 Keeper 구성 요소가 필요합니다.
다음 다이어그램은 6대의 서버로 구성된 ClickHouse 클러스터를 보여 줍니다. 여기서 앞서 소개한 두 개의 테이블 세그먼트 Shard-1 및 Shard-2에는 각각 3개의 레플리카가 있습니다. 이 클러스터로 쿼리가 전송됩니다.
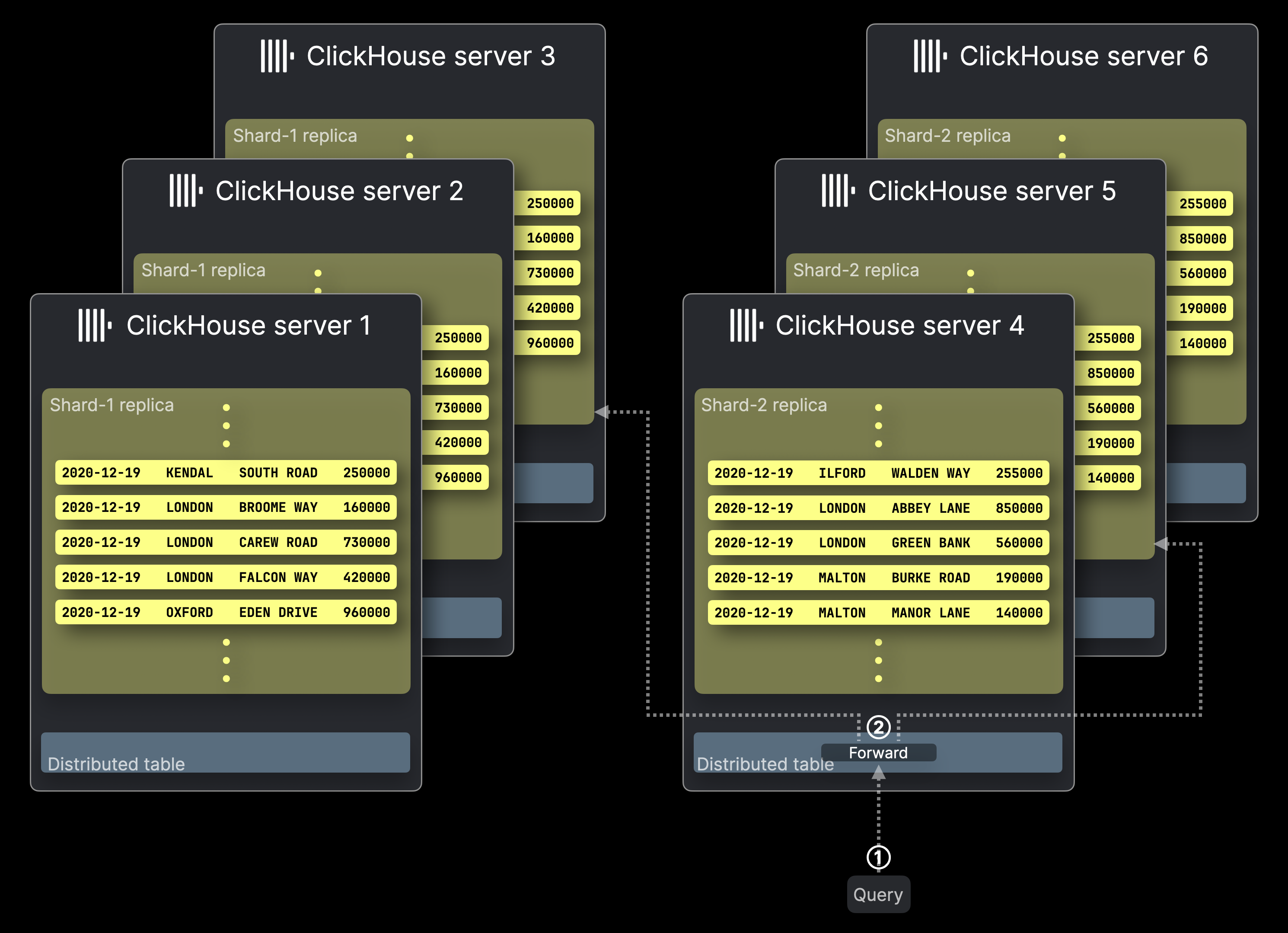
쿼리 처리는 레플리카가 없는 구성과 비슷하게 동작하며, 각 세그먼트에서 단 하나의 레플리카만 쿼리를 실행합니다.
레플리카는 데이터 무결성과 failover를 보장할 뿐만 아니라, 여러 쿼리를 서로 다른 레플리카에서 병렬로 실행할 수 있게 하여 쿼리 처리량도 향상시킵니다.
① 분산 테이블을 대상으로 하는 쿼리가 직접 또는 로드 밸런서를 통해 해당 ClickHouse 서버로 전송됩니다.
② 분산 테이블은 쿼리를 각 세그먼트의 레플리카 하나로 전달하며, 선택된 레플리카를 호스팅하는 각 ClickHouse 서버는 로컬 쿼리 결과를 병렬로 계산합니다.
나머지 동작은 레플리카가 없는 구성과 동일하며 위 다이어그램에는 표시되지 않았습니다. 처음 쿼리 대상이 된 분산 테이블을 호스팅하는 ClickHouse 서버는 모든 로컬 결과를 수집하고, 이를 머지하여 최종 전역 결과로 만든 다음 쿼리 발신자에게 반환합니다.
ClickHouse에서는 ②에 대한 쿼리 전달 전략을 구성할 수 있습니다. 기본적으로는 — 위 다이어그램과 달리 — 분산 테이블이 사용 가능한 경우 로컬 레플리카를 선호하지만, 다른 로드 밸런싱 전략도 사용할 수 있습니다.
추가 정보를 얻을 수 있는 곳
테이블 세그먼트와 레플리카에 대한 이 개요 수준의 소개를 넘어 더 자세한 내용을 확인하려면 배포 및 스케일링 가이드를 참고하십시오.
또한 ClickHouse 세그먼트와 레플리카를 더 깊이 이해하는 데에는 다음 튜토리얼 동영상을 시청할 것을 강력히 권장합니다:
